一、引言
1) 背景
1. 3D 感知的现实需求:既要“看得清”,也要“看得稳”
许多机器人/自动驾驶的 3D 感知任务(如定位、建图、避障与目标检测)依赖高质量的三维几何信息。 激光雷达(LiDAR)能够提供高分辨率点云,但通常成本更高,且在雨雾、强光等环境下性能容易受影响,部分平台部署也受到体积/功耗/预算等限制。 相比之下,毫米波雷达成本更低、全天候鲁棒,在黑暗、雨雾等情况下优势明显,因此在实际系统中越来越常见。
2. 核心痛点:雷达点云稀疏且噪声大,直接用于 3D 感知很吃力
尽管雷达鲁棒性强,但其点云质量与 LiDAR 相比差距明显:空间分辨率更低、点数更少; 同时角度(方位/俯仰)方向的不确定性更强,噪声更显著,导致几何结构细节更难恢复, 例如墙体边缘、柱子以及细薄结构往往呈现缺失或模糊,从而限制下游感知算法的性能上限。
3. 现有方法的局限:体素化太重、细节易损;点云集合又难直接扩散 ,为了从雷达生成更高质量的 3D 表达,已有方法大致有两类思路:
(1)先把 3D 空间离散成稠密体素/网格再进行生成,这样做实现相对直接,但计算与内存开销昂贵; 当体素分辨率受限时,高频几何细节(如薄结构、锐边)容易被“抹平”。
(2)直接在点云上进行生成,但点云本质是无序集合,难以用常规生成框架稳定建模; 同时场景级点云规模大,若直接在原空间做扩散,训练与推理成本会更高。
2) 预备
Inroad
为了从雷达谱图生成高保真三维点云,论文采用“先压缩、再生成”的思路:将场景级 LiDAR 点云压到一个紧凑的 latent 空间, 在 latent 上进行扩散生成,从而避免在原始 3D 体素空间进行高成本的“硬扩散”。这样既能保留点云结构表达能力,又显著降低计算与内存开销。
同时,条件信息不使用稀疏且噪声较大的雷达点云,而是直接利用更丰富的雷达谱图(radar spectrum)作为引导信号。 雷达谱图包含更原始的回波强度与空间线索,能够从源头提供更多几何提示,帮助扩散模型生成更接近 LiDAR 的点云细节。
在扩散模型结构上,论文选择 DiT(Diffusion Transformer)作为去噪网络:可以理解为在 latent diffusion(LDM)框架下, 用 Transformer(而不是传统 U-Net)来建模去噪过程。经典的文生图系统(如 Stable Diffusion)通常采用 CLIP 编码文本作为条件, 并以 U-Net 作为去噪器;而 DiT 更适合处理 token/序列形式的 latent 表示,并提供多种条件注入方式(如自适应归一化、交叉注意力、上下文 token)。
Preliminary
1. Latent Diffusion Model(LDM)基本原理
LDM 的核心是“在潜空间做扩散”。先用编码器把高维数据 x(图像或点云等)压缩为潜变量 z, 即 z = E(x);扩散过程在 z 上进行:训练时逐步加噪得到 z_t,并训练去噪网络预测噪声; 推理时从随机噪声出发,逐步去噪得到 z_0,最后通过解码器 D(z_0) 还原回原空间数据。 这种做法的优势是:扩散的高成本操作发生在更低维、更紧凑的 latent 空间,从而显著提升效率。
2. 条件扩散(Conditional Diffusion)
条件扩散指在去噪过程中引入外部条件信息 c(例如文本、图像特征、传感器特征等),让生成结果满足观测约束。 在 Stable Diffusion 中,条件通常来自 CLIP 文本编码器;在本文任务中,条件来自雷达谱图特征(radar spectrum guidance), 用于向扩散模型注入语义与几何线索,指导其生成“与雷达观测一致”的点云 latent 表示。
3. DiT(Diffusion Transformer)作为去噪网络
DiT 将 latent 表示切分为 token(或 patch token),并用多层 Transformer block 建模去噪函数。 相比 U-Net,DiT 更天然适配“token/序列”形式的 latent,并便于融合多模态条件。 如图中示意,DiT block 常见有三种条件注入变体:
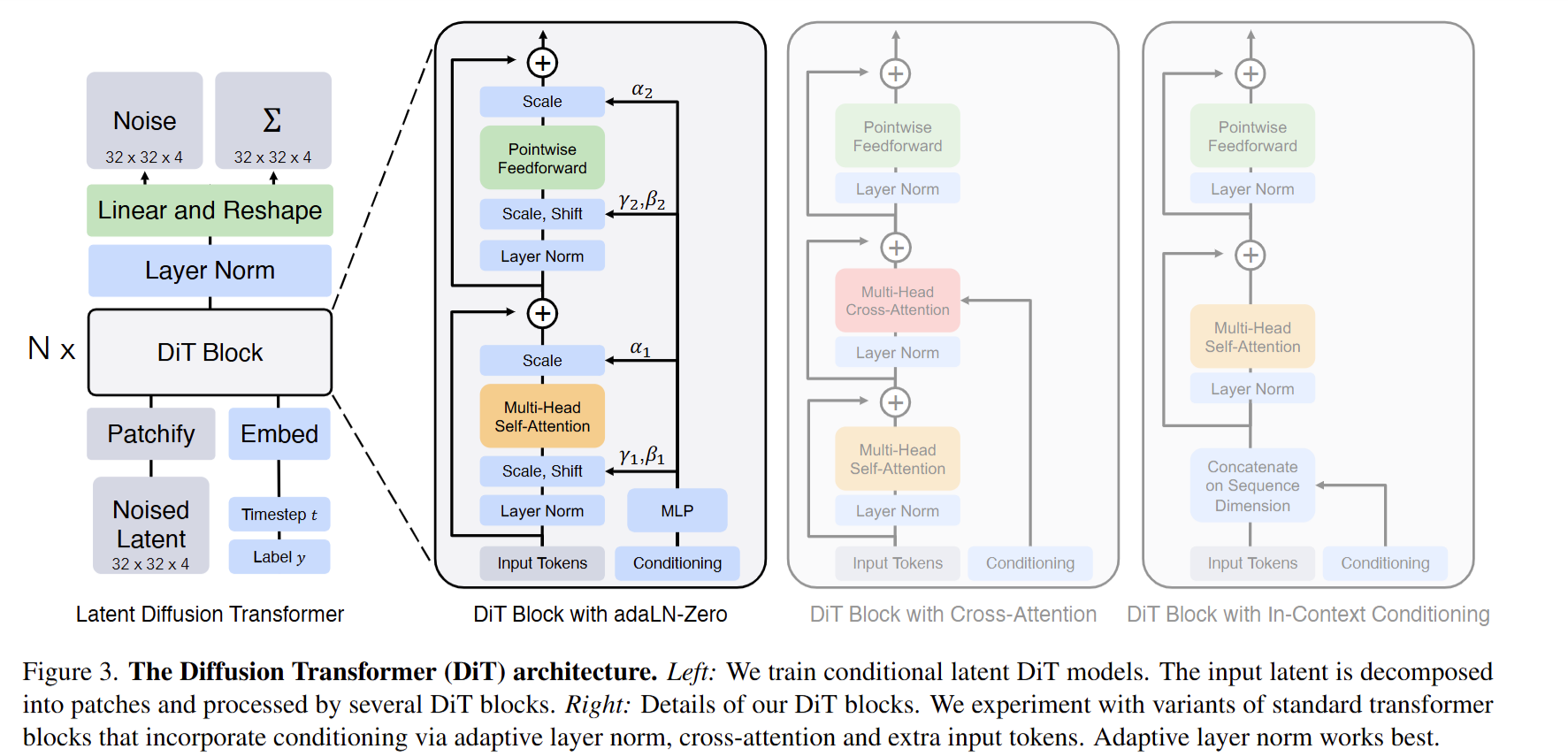
- adaLN / adaLN-Zero:通过自适应 LayerNorm 的 scale/shift 将条件信号注入到每个 block(更像“调制”网络内部表征)。
- Cross-Attention:在 Transformer block 中加入交叉注意力层,让 latent token 与条件 token 交互。
- In-Context Conditioning:把条件 token 直接拼接到输入序列中,作为额外上下文参与自注意力计算。
二、方法
1) 系统概览
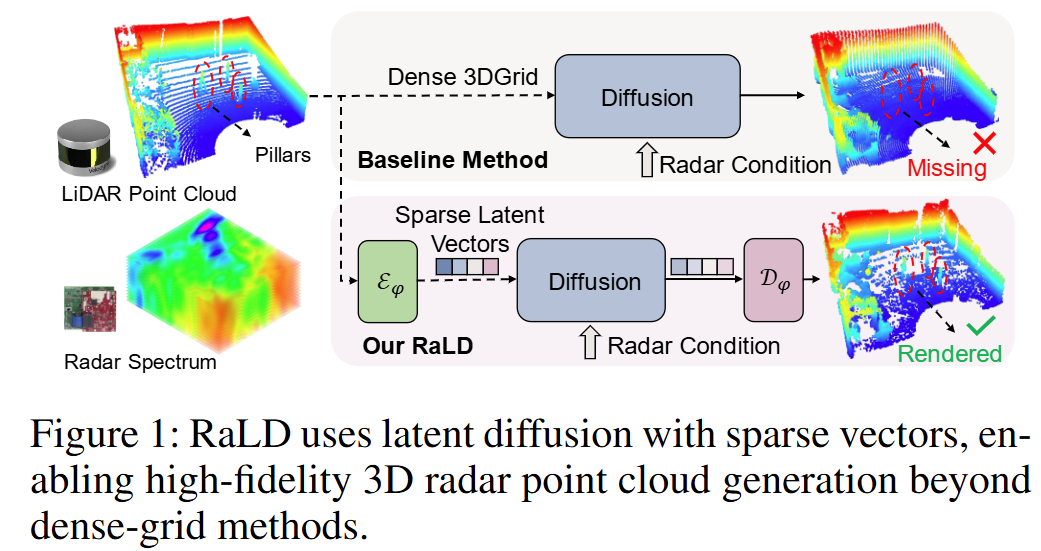
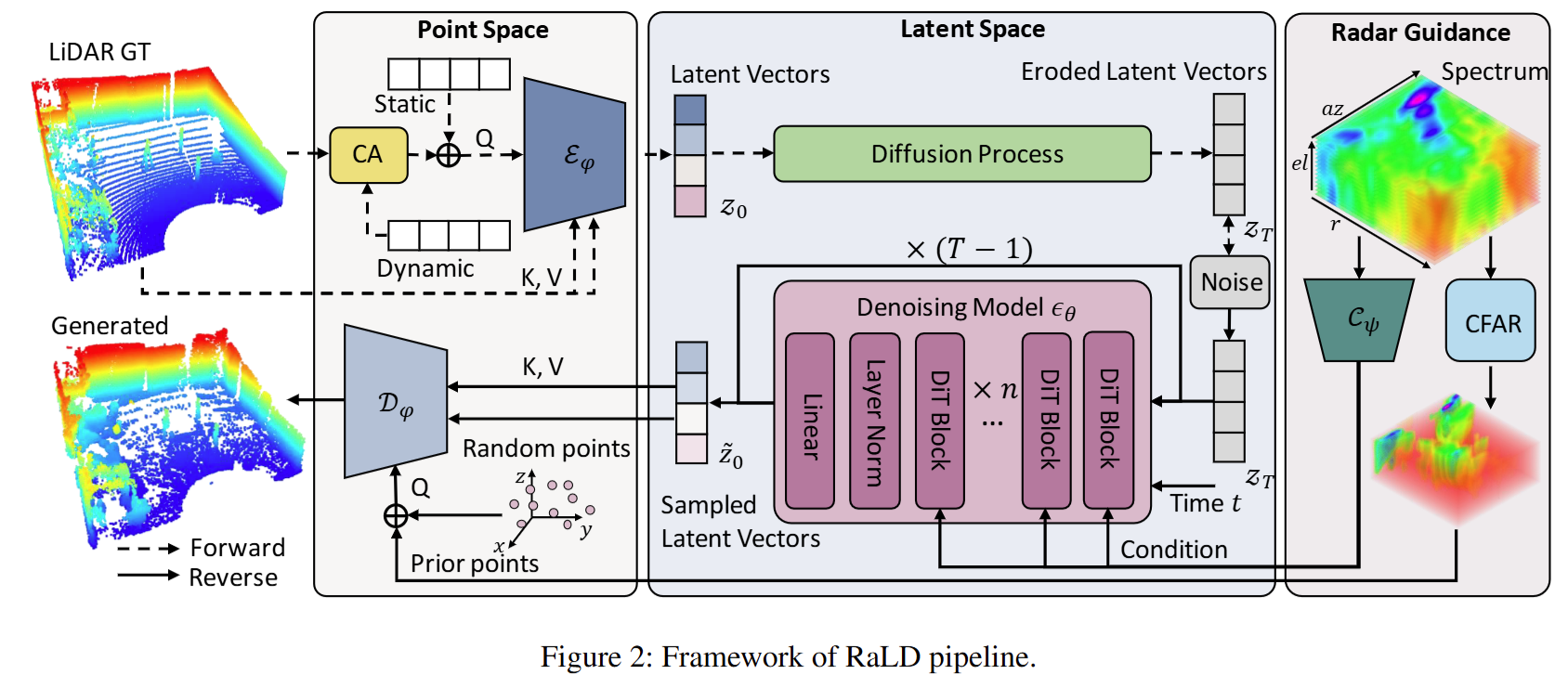
Goal:用雷达谱图补全出像 LiDAR 一样细的 3D 点云。
整体思路是一个“雷达条件的潜空间扩散生成”流水线:先把 LiDAR 场景点云压缩到紧凑的 latent 空间, 在 latent 上进行扩散采样并用雷达谱图提供条件引导,最后再将生成的 latent 解码回稠密点云。
Autoencoder:将 LiDAR 场景点云压缩为结构化 latent 表示。
编码器把场景级点云映射为一组紧凑的 latent tokens(便于后续扩散建模),解码器则通过预测空间查询点的 occupancy 来重建点云, 从而实现“点数可控、细节可恢复”的重建方式。
Latent diffusion:在 latent 空间进行扩散采样,并由雷达谱图特征引导生成。
扩散模型学习在潜空间中从噪声逐步去噪生成点云 embedding;条件信息来自雷达谱图的高层特征, 用于注入语义与几何线索,使生成结果与雷达观测一致。
Decoder:通过 occupancy 查询重建点云,并用 CFAR 提供候选区域先验提升效率与质量。
由于场景空间巨大,解码阶段无法对全空间进行密集查询。系统利用低阈值 CFAR 从雷达谱图中提取候选目标区域, 优先在这些区域采样查询点进行 occupancy 预测,从而减少空旷区域的无效计算;同时保留部分随机查询点以补全漏检或弱反射结构。
2) 视锥 LiDAR自编码器
为什么需要“专门的”场景级 LiDAR 压缩器?
场景级 LiDAR 点云极度稀疏且结构不规则。为了在 latent 空间做扩散生成,首先需要一个足够鲁棒的自编码器将点云压缩成紧凑表示, 否则扩散阶段难以稳定学习。
用“latent 向量集 + occupancy 查询”来重建点云
编码器将场景点云压缩为一组潜在向量(latent token set)。解码器不直接输出固定 N 个点坐标, 而是对空间中的 query 点预测 occupancy(是否被占据),再从高 occupancy 的点中恢复出点云,从而实现点数可控的高保真重建。
Occupancy 标签:体素 (voxel) 的问题
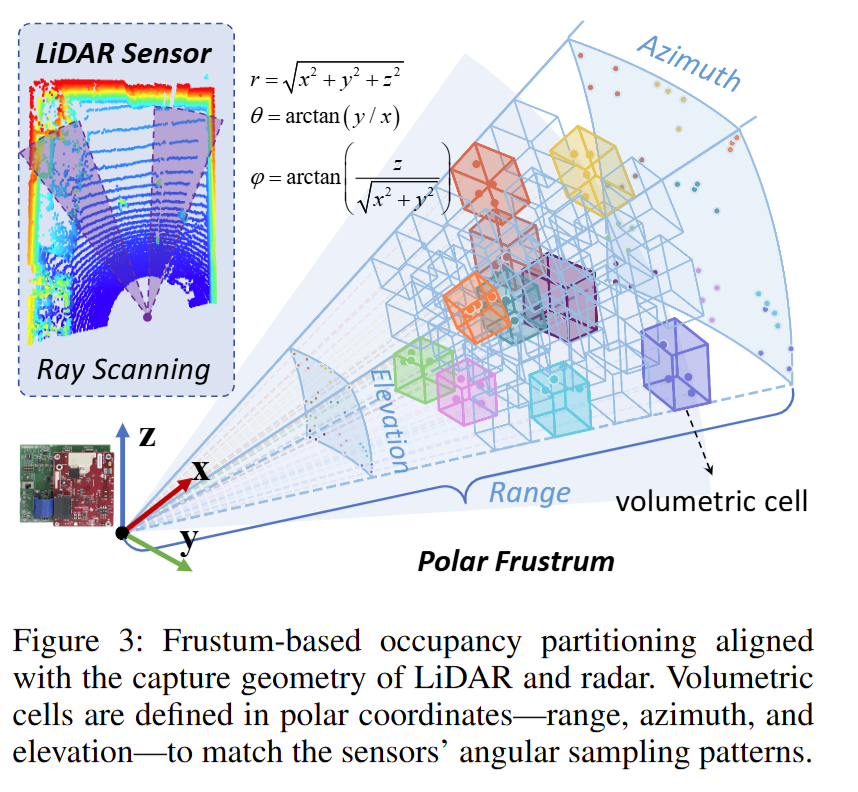
常见做法是在笛卡尔坐标系里用体素网格定义占据:若 query 点所在体素包含至少一个 LiDAR 回波,则认为该 query 点占据。 但 LiDAR 是固定角分辨率的射线扫描,近处点密、远处点稀;均匀笛卡尔体素与传感器采样机制不对齐。
视锥 (frustum) 分区:按极坐标定义 occupancy
为贴合 LiDAR 的角度采样规律,论文在极坐标(range / azimuth / elevation)下把空间切成视锥体元(frustum cells), 让跨深度的空间表达更规律,并便于后续与雷达谱图对齐。
\[ r=\sqrt{x^2+y^2+z^2},\quad \theta=\arctan\left(\frac{y}{x}\right),\quad \phi=\arctan\left(\frac{z}{\sqrt{x^2+y^2}}\right) \]
其中 \(r\) 为距离(range),\(\theta\) 为方位角(azimuth),\(\phi\) 为俯仰角(elevation)。
\[ F_{i,j,k}=\left\{(r,\theta,\phi)\ \middle|\ \begin{aligned} &r\in[r_i,r_{i+1})\subseteq[r_{\min},r_{\max}]\\ &\theta\in[\theta_j,\theta_{j+1})\subseteq[\theta_{\min},\theta_{\max}]\\ &\phi\in[\phi_k,\phi_{k+1})\subseteq[\phi_{\min},\phi_{\max}] \end{aligned} \right\} \]
每个 frustum 体元由 \([r_i,r_{i+1})\)、\([\theta_j,\theta_{j+1})\)、\([\phi_k,\phi_{k+1})\) 三个区间共同界定, 对应某一角度方向上的一段局部空间体积。
\[ O_{i,j,k}= \begin{cases} 1,& \exists p\in P\ \text{s.t.}\ p\in F_{i,j,k}\\ 0,& \text{otherwise} \end{cases} \]
\[ O(q)=O_{i,j,k}\quad \text{if}\ q\in F_{i,j,k} \]
即:只要某个 frustum 内存在 LiDAR 点,就记为 occupied;query 点 \(q\) 的 occupancy 由其所属 frustum 的 occupancy 决定。
为什么 frustum 更利于学习遮挡(occlusion)?
在同一条角向射线(固定 \(\theta,\phi\))方向上,被占据的 frustum 往往首先出现在更靠近传感器的位置, 这种“沿射线的前后顺序”让遮挡关系更显式,因而更容易被模型学习。 同时,极坐标 frustum 划分也与雷达谱图的极坐标表示更一致,便于后续把谱图作为扩散条件进行对齐与引导。
3) 顺序不变的潜编码
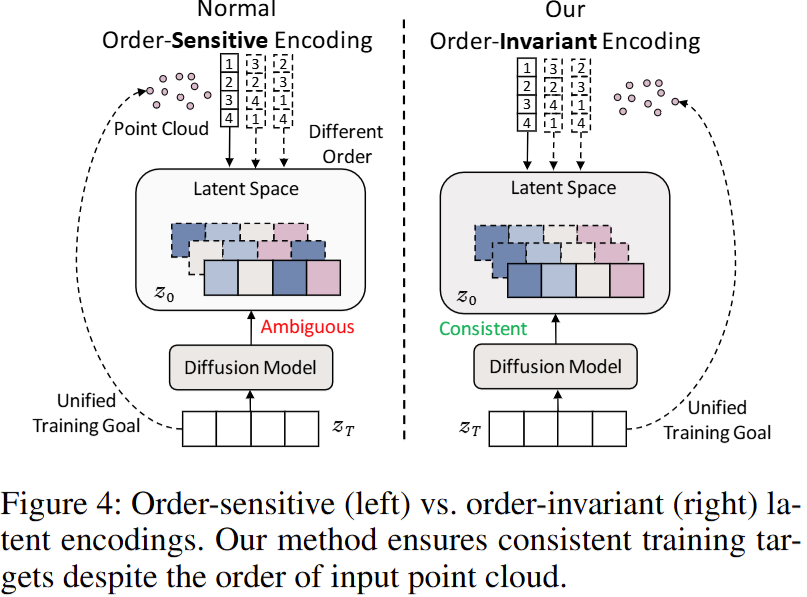
动机:为什么要强调“顺序不变”?
虽然视锥(frustum)自编码器能够得到紧凑且与传感器几何对齐的 latent 表示,但点云本质上是无序集合: 同一个点云 \(P\) 的任意排列(permutation)都应表示相同的几何结构。 因此,编码得到的 latent token 也应尽量对输入点的顺序不敏感,否则会影响后续 latent diffusion 的稳定性与泛化。
问题:顺序敏感会如何“破坏”扩散训练?
扩散模型训练的目标通常是:在每个时间步预测加到 latent 上的噪声。若编码器对点顺序敏感, 那么同一个几何(同一个样本)在不同点顺序下会产生不同的 latent tokens,进而导致噪声监督目标不一致: 即使几何不变,训练目标也会变化,从而改变同一样本的优化轨迹,削弱去噪函数的稳定学习与可泛化性。 论文在 Figure 4 中将这种“目标歧义/不一致(ambiguous)”直观展示出来。
解决方案:Hybrid Queries(静态锚点 + 动态查询)
论文的核心思路是控制输入到 cross-attention 编码器的 query tokens,从而让 latent token 的结构与顺序保持一致。 与仅使用随机 queries 或仅使用固定 learned queries 不同,作者采用 hybrid 策略:
1.静态 queries \(Q_s\):一组固定的可学习 token,作为“稳定锚点”,保证跨样本、跨 permutation 的 token 顺序一致;
2.动态 queries \(Q_d\):从输入点云 \(P\) 通过可学习投影得到,注入与当前几何相关的细节特征;
3.二者融合得到最终编码 queries,使 latent 表示既“顺序稳定”又“几何自适应”。
\[ Q_{\text{enc}}=\mathrm{Proj}\Bigl(Q_s+\mathrm{CrossAttn}(Q_d, P)\Bigr). \]
其中 \(Q_s\in\mathbb{R}^{M\times d}\) 提供一致的 token 结构,\(\mathrm{CrossAttn}(Q_d,P)\) 将点云几何信息注入到 queries, \(\mathrm{Proj}(\cdot)\) 用于映射到编码器所需的维度空间。 该设计通过固定 query 结构保证顺序不变性,同时提升几何表达能力,使扩散建模更有效。
4) 雷达频谱引导
Diffusion Conditioned on Radar Spectrum
目的:把雷达观测中的语义与几何线索注入到 latent diffusion 中,作为条件引导生成。
雷达输入形式:雷达频谱(radar spectrum)可表示为极坐标下的 3D 张量(range / azimuth / elevation),强度高通常对应更强的表面反射。
挑战:各向异性噪声雷达信号天然噪声大,且不确定性呈各向异性:通常 range 更可靠,而角度(az/el)更不可靠。
做法:az/el 上采样 + 卷积编码器 Cψ 提特征
为了缓解角向噪声,方法在方位角与俯仰角维度对频谱进行上采样,并使用卷积编码器 \(C_\psi\) 提取鲁棒的高层特征。该设计扩大了有效感受野,从而抑制角向噪声,同时更突出可靠的距离信息; 得到的 feature map 作为紧凑、noise-aware 的雷达条件表示。
条件如何喂给扩散模型(DiT):
由于 latent 表示是 1D token(向量序列/集合),论文采用 transformer-based 的 DiT 作为扩散去噪网络; 将雷达特征加入 3D positional embedding 以保留空间结构,然后 flatten 成与 latent token 兼容的形状, 作为条件输入,使扩散模型学习 latent tokens 与雷达信号之间的空间对应关系。
\[ S\in\mathbb{R}^{R\times A\times E},\quad F=C_\psi(S),\quad c=\mathrm{Flatten}(\mathrm{PE}_{3D}(F)) \]
其中 \(S\) 为雷达频谱张量,\(F\) 为卷积编码器特征,\(c\) 为送入扩散模型的条件序列表示(示意性写法)。
Decoding with Radar-Guided Query Initialization
问题:扩散采样得到 latent 后,还需要解码为点云。由于场景级点云极稀疏,即便自编码器使用高分辨率 frustum, 解码时若对整个 3D 空间进行密集查询,需要评估“千万级”query 点,计算不可承受。
策略:用 CFAR 给解码 query 提供空间先验
为提升效率,论文在雷达频谱上应用低阈值 CFAR,得到候选目标区域;这些检测结果用于指导解码阶段 query 点的选取。 虽然 CFAR 并不完美,但能提供较强的目标位置先验,显著减少空旷区域的无效查询。
完整性保障:加入全空间随机 query
为避免漏检(例如低反射结构或未被 CFAR 检出的区域),方法额外在全 3D 空间随机采样一部分 query 点, 让解码器仍有机会覆盖这些结构。
\[ \mathcal{Q}=\mathcal{Q}_{\text{free}}\ \cup\ \mathcal{Q}_{\text{CFAR}} \]
推理阶段采样规模(实现细节):论文在推理时从 free space 采样约 500k 个 query 点,并从 CFAR 区域采样约 700k 个 query 点来引导解码。
三、实验
1) 实验配置
本文在 ColoRadar 数据集上评估方法。该数据集提供雷达频谱(radar spectrum)与 LiDAR 点云的配对数据, 覆盖实验室、走廊等多种室内场景,每个场景包含多条序列。训练/验证/测试划分方式为:使用每个场景中较早的序列进行训练, 保留最后两条序列用于验证与测试。为对齐雷达与 LiDAR 数据,预处理包括:剔除不重叠帧;使用标定参数将 LiDAR 点云变换到与雷达一致的坐标系; 裁剪点云以匹配雷达视场(FoV);最后将点云转换到极坐标表示。 自编码器部分采用视锥(frustum)占据划分,分辨率设置为:range 0.05 m、azimuth 0.25°、elevation 0.5°; 点云坐标归一化到 [-1, 1]。训练时将点云下采样到 10,000 点,并使用同样数量(10,000)的 decoder query 点。 为缓解稀疏性,query 中 6.25% 为正样本,其余为随机负样本。编码后的 latent 表示为 512 个 token,每个 token 维度为 32。 自编码器训练 150 epochs,batch size 为 28。扩散模型训练 100 epochs,batch size 为 16,并使用 EDM sampler。 推理阶段,为引导解码过程,从 free space 采样 500k 个 query 点,并从 CFAR 区域采样 700k 个 query 点。 实现基于 PyTorch,训练使用 2 张 NVIDIA RTX 4090 GPU。训练耗时:自编码器约 28 小时,扩散模型约 60 小时。 评价指标使用 Chamfer Distance(CD)与 Earth Mover’s Distance(EMD),用于衡量生成点云与 GT 点云的相似度: CD 表征两组点云之间的平均距离;EMD 表征将一个点分布“搬运”到另一个点分布的最小代价(更关注整体分布匹配),两项指标均是数值越低越好。
2) 结果
Main Results
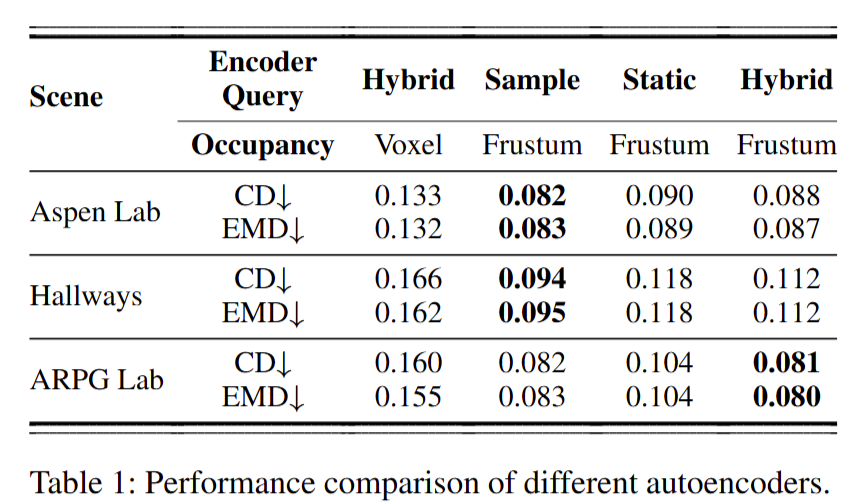
Autoencoder(Table 1):在 Aspen Lab、Hallways、ARPG Lab 三个场景上对比不同自编码器设计。 结果显示,frustum-based 的 occupancy 划分显著优于 voxel-based, 最大带来 CD↓49.6%、EMD↓48.3% 的提升;在 frustum 设置下, hybrid query 在所有场景都优于 static query,并接近 downsampled point query 的重建效果, 说明其既保持顺序不变特性,也为后续扩散生成提供更高上限。
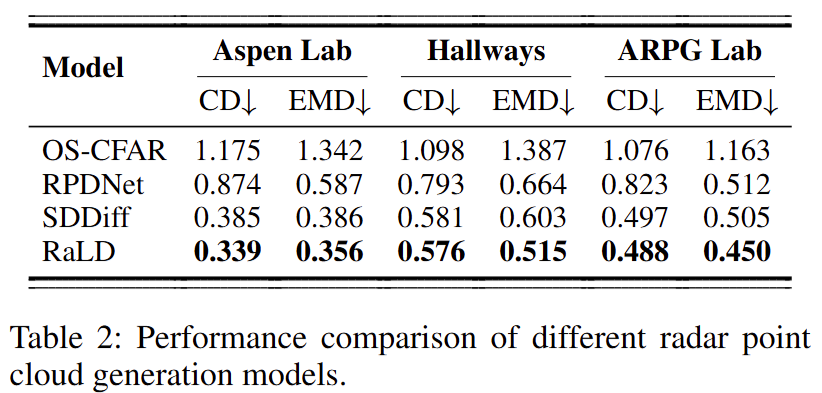
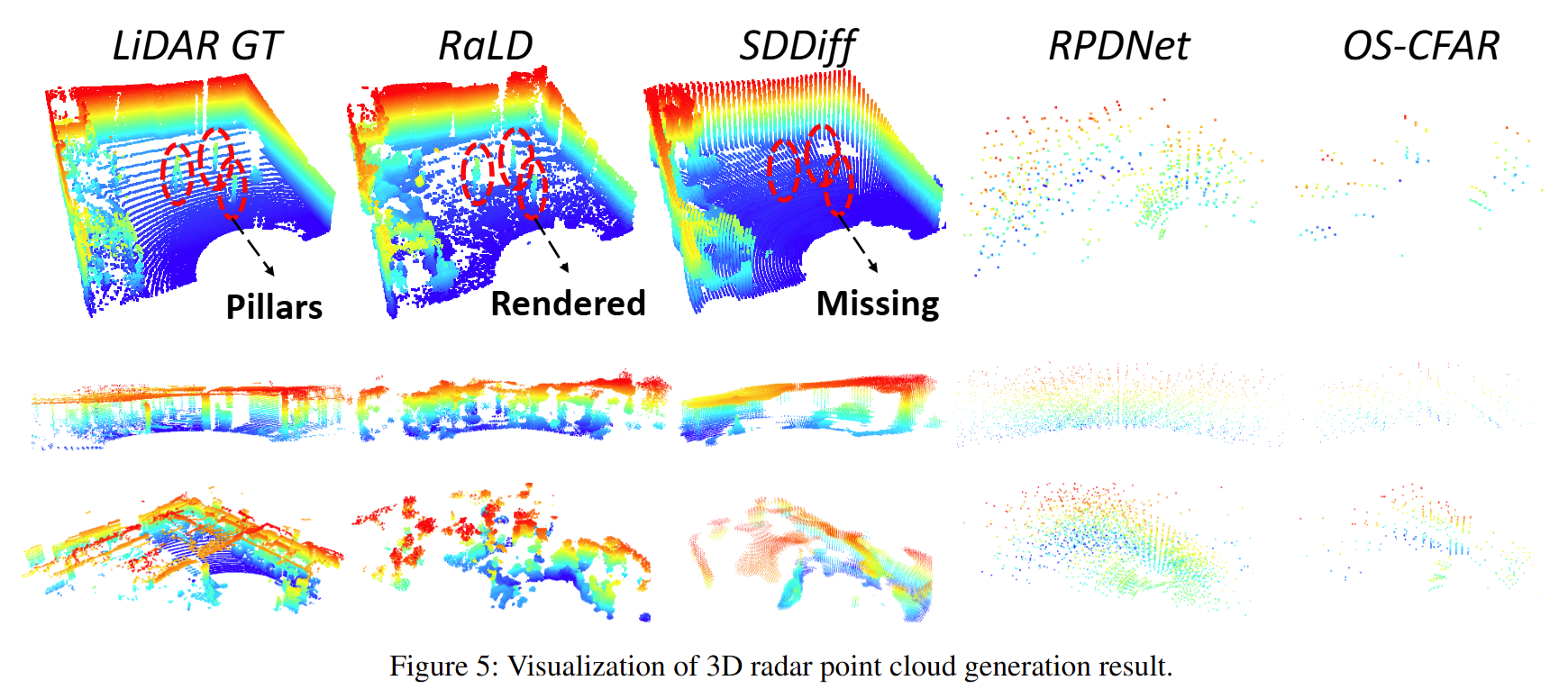
端到端生成(Table 2 & Figure 5):RaLD 在所有场景均优于基线方法, 相比次优方法 SDDiff,在 Aspen Lab / Hallways 上最高达到 CD↑11.9% 与 EMD↑14.6% 的改进。 定性结果表明 RaLD 输出更锐利、更能保留柱子和墙边缘等高频结构,而 SDDiff 往往更平滑且易丢关键结构细节。
Ablation Studies and Additional Results
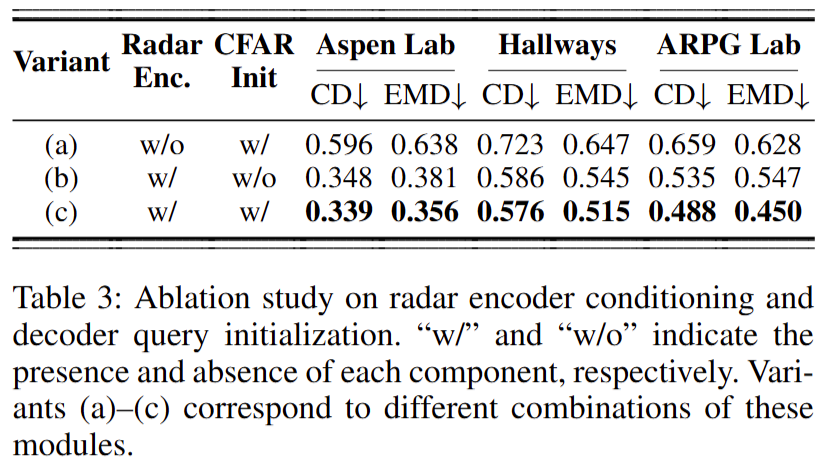
消融(Table 3):评估两项关键组件——雷达 encoder 条件(radar encoder conditioning)与解码 query 初始化(CFAR)。 同时启用两者的配置在各场景均取得最佳结果;其中雷达 encoder 有助于提取更稳健的谱图特征、缓解 raw spectrum 噪声, CFAR 初始化则提供目标位置先验,减少空旷区域无效查询并提升生成质量。
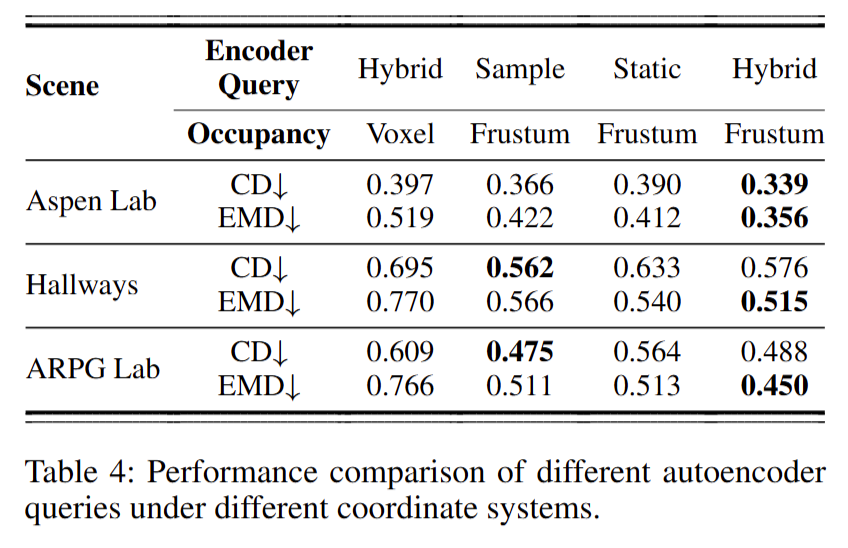
AE 设计对生成的影响(Table 4):在不同坐标系与 query 策略对比中, frustum + hybrid query 的扩散模型在 EMD 上跨场景最优,CD 在部分场景也达到最佳或相当水平。 论文指出 CD 更易受点密度与离群点影响,而 EMD 更能反映整体结构质量;因此该配置带来的稳定 EMD 改善说明结构重建更可靠。
3) 额外实验
未见室内场景(Unseen Indoor Scenarios)
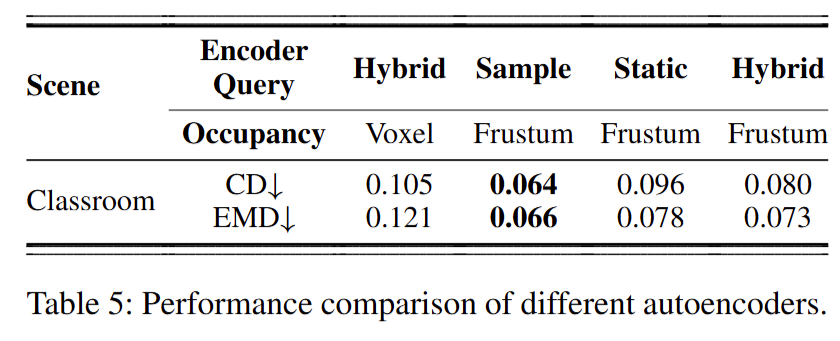
为验证泛化能力,作者在 SDDiff 的室内数据集上评估模型,并在未见室内场景上测试自编码器(不进行微调)。 Table 5 显示:frustum-based occupancy + hybrid encoder 的表现优于 static encoder 与 voxel-based 划分, 且相比已见室内场景的性能下降不明显,说明该自编码器对未见室内场景具有较好泛化能力。
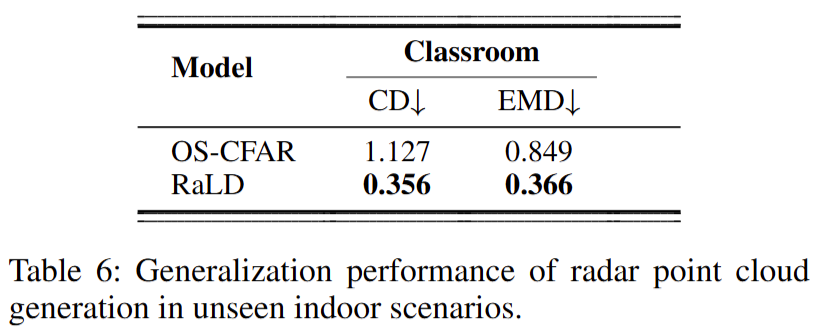
对于端到端雷达点云生成模型,作者在未见室内场景上进行 20 epochs 微调。 Table 6 表明:仅少量微调即可达到与已见场景接近的表现,进一步验证了方法的可迁移性。
未见室外场景(Unseen Outdoor Scenarios)
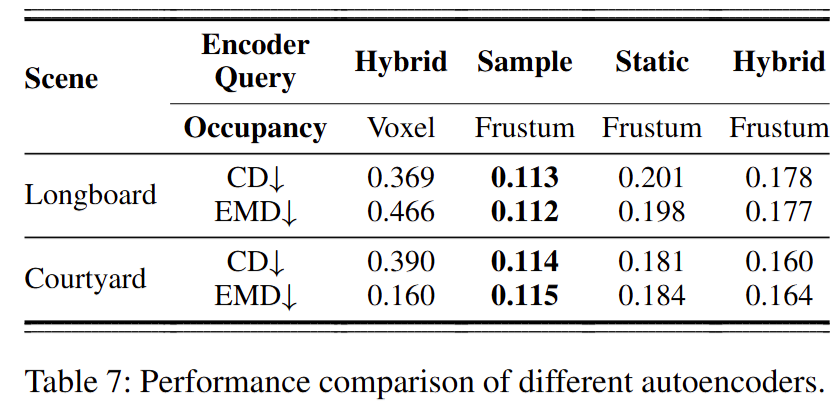
作者进一步在 ColoRadar 数据集的未见室外场景上测试泛化能力。Table 7 显示:与室内相比,所有自编码器在室外场景均出现性能下降, 反映室外点云更稀疏、结构更复杂。与此同时,voxel-based 划分在室外的退化更明显,说明其对室外环境尤为不适配; 在 frustum-based 划分下,hybrid encoder 仍优于 static encoder,体现出更强的泛化能力。
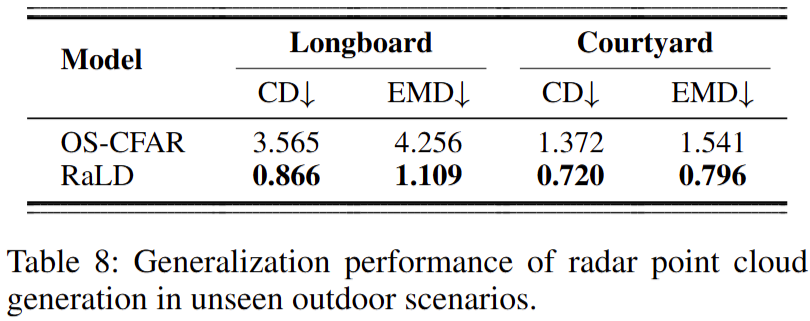
随后作者在两个室外场景(Longboard、Courtyard)上进行 20 epochs 微调(Table 8)。 虽然绝对性能仍低于室内,但微调后的模型依旧显著优于 OS-CFAR 基线。作者认为室外稀疏性与复杂度更高, 以及自编码器质量下降,都会限制最终生成表现。
模型可扩展性(Model Scalability)
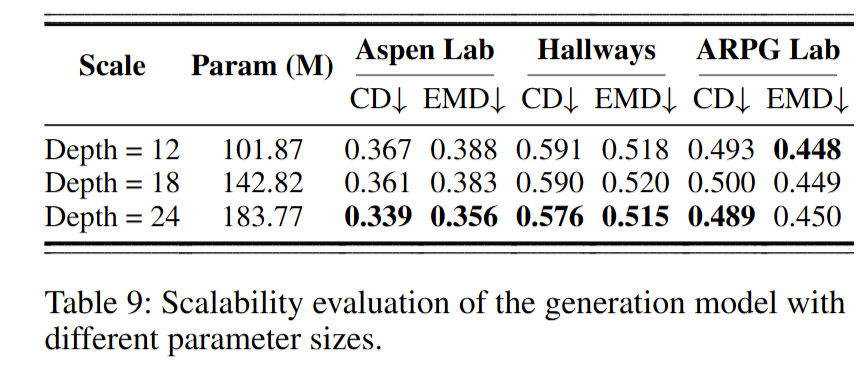
作者通过改变扩散模型中 DiT blocks 的数量评估可扩展性(Table 9)。 结果表明:随着 DiT 深度增加,性能在多数情况下提升,但增益并不显著; 当 block 数达到 24 时性能趋于饱和,因此论文默认采用 24 个 DiT blocks 作为主要设置。
生成性能的补充结果(Additional Results on Generation Performance)
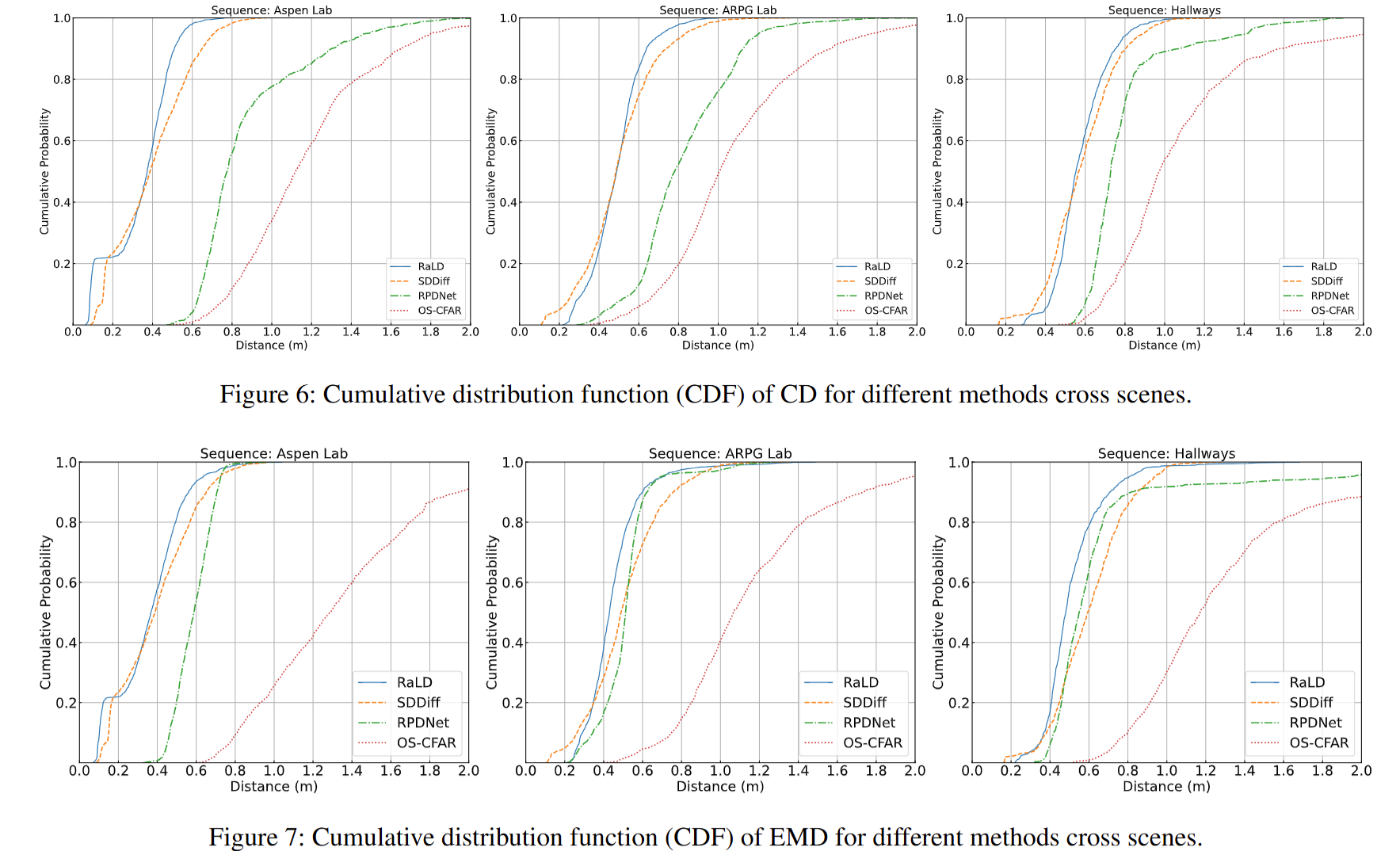
作者额外给出了主实验中 CD 与 EMD 的 CDF 曲线(Figure 6 与 Figure 7),用于更细粒度地展示不同方法在误差分布上的整体表现。